최근에 Stable Diffusion 구조 공부하다가 VAE(Variational Autoencoder)가 계속 등장해서 제대로 정리해보고 싶어졌다. GAN이나 Diffusion 모델에 비해 덜 주목받는 편이지만, 사실 생성 모델의 핵심 개념이 거의 다 녹아 있는 알고리즘이다.
이번 글에서는 VAE의 개념부터 ELBO, Reparameterization Trick, 잠재 공간의 의미, 그리고 PyTorch로 직접 구현해서 이미지를 생성하는 것까지 한 번에 정리해본다. 레츠꼬 🎨
1. VAE(Variational Autoencoder)란? — Autoencoder와의 차이부터
일반 Autoencoder(AE)는 입력 데이터를 압축(인코딩)했다가 다시 복원(디코딩)하는 구조다.
중간에 압축된 표현을 잠재 벡터(Latent Vector)라고 하는데, 문제는 이 잠재 공간이 불연속적(discontinuous)이라는 것이다. 학습 데이터가 없는 빈 영역에서 샘플링하면 의미 없는 이미지가 나온다. 새로운 데이터를 생성하기 어렵다는 뜻이다.
VAE는 이 문제를 해결하기 위해 잠재 벡터를 고정된 하나의 점이 아니라 확률 분포(probability distribution)로 표현한다. 평균과 분산을 학습하고 거기서 z를 샘플링해서 디코더에 넘기는 방식이다. 덕분에 잠재 공간이 매끄럽게 연결되고, 임의의 z를 샘플링해도 그럴한 이미지가 나오게 된다.

위 그림처럼 AE는 잠재 벡터 z 하나를 고정값으로 출력하는 반면, VAE는 평균과 분산 두 개를 출력하고 거기서 샘플링한다. 손실 함수도 AE는 재구성 손실만 쓰는 반면 VAE는 Reconstruction Loss + KL Divergence 두 항을 합산한다.
2. Reparameterization Trick과 ELBO(Evidence Lower BOund)
VAE의 학습 목표는 주어진 데이터 x의 로그 가능도 log p(x)를 최대화하는 것이다.
그런데 log p(x)를 직접 계산하는 건 잠재 변수 z에 대한 적분이 포함돼서 계산이 불가능하다(intractable).
그래서 log p(x)의 하한(lower bound)을 대신 최대화하는데, 이게 바로 ELBO(Evidence Lower BOund)다.
$$\log p(x) \geq \mathbb{E}_{q_\phi(z|x)}[\log p_\theta(x|z)] - D_{KL}(q_\phi(z|x) \| p(z))$$
ELBO를 분해하면 두 항이 나온다.
① Reconstruction Term — 디코더가 x를 얼마나 잘 복원하는지
② Regularization Term — 인코더 분포가 표준 정규분포에서 얼마나 벗어났는지
여기서 학습 시 중요한 문제가 하나 있다. 샘플링 z ~ q(z|x) 은 미분이 안 되는 연산이라 역전파가 막힌다.
이걸 해결하는 게 바로 Reparameterization Trick이다.
epsilon을 표준 정규분포에서 따로 샘플링하고 아래처럼 분리하면, 미분이 필요한 건 mu와 sigma뿐이라 역전파가 정상적으로 흐른다.
$$z = \mu + \sigma \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0, I)$$
이 트릭이 없으면 VAE 학습 자체가 불가능하다.

3. 손실 함수 코드로 보기
ELBO를 최소화 문제로 바꾸면 최종 손실 함수는 아래 두 항의 합이다.
가우시안 분포일 때 KL Divergence는 닫힌 형태(closed-form)로 계산할 수 있다.
$$\mathcal{L} = \underbrace{-\mathbb{E}[\log p_\theta(x|z)]}_{\text{Reconstruction Loss}} + \underbrace{D_{KL}(q_\phi(z|x) \| \mathcal{N}(0,I))}_{\text{KL Divergence}}$$
가우시안 분포 가정 하에 KL Divergence는 아래처럼 닫힌 형태로 계산된다.
$$D_{KL} = -\frac{1}{2} \sum_{j=1}^{d} \left(1 + \log\sigma_j^2 - \mu_j^2 - \sigma_j^2\right)$$
코드로 쓰면 이렇게 된다.
def vae_loss(recon_x, x, mu, log_var):
# ① Reconstruction Loss (BCE)
BCE = F.binary_cross_entropy(recon_x, x, reduction='sum')
# ② KL Divergence (closed-form for Gaussian)
# = -0.5 * sum(1 + log_var - mu^2 - exp(log_var))
KLD = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
return BCE + KLD
두 손실이 균형을 이뤄야 좋은 생성 모델이 된다.
Reconstruction Loss만 크면 잠재 공간이 불규칙해지고, KL Loss만 크면 이미지가 뭉개진다.
실전에서는 KL Loss 앞에 beta 가중치를 두는 beta-VAE 기법을 쓰기도 한다.
4. PyTorch로 VAE 모델 구현하기
MNIST 손글씨 데이터셋 기준으로 VAE를 구현한다. 784차원 입력(28x28)을 latent_dim=20짜리 잠재 공간으로 압축하는 구조다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class VAE(nn.Module):
def __init__(self, input_dim=784, hidden_dim=400, latent_dim=20):
super().__init__()
# Encoder: x -> h -> (mu, log_var)
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc_mu = nn.Linear(hidden_dim, latent_dim) # 평균
self.fc_logvar = nn.Linear(hidden_dim, latent_dim) # 로그 분산
# Decoder: z -> h -> x_hat
self.fc3 = nn.Linear(latent_dim, hidden_dim)
self.fc4 = nn.Linear(hidden_dim, input_dim)
def encode(self, x):
h = F.relu(self.fc1(x))
return self.fc_mu(h), self.fc_logvar(h)
def reparameterize(self, mu, log_var):
std = torch.exp(0.5 * log_var) # sigma
eps = torch.randn_like(std) # eps ~ N(0, I)
return mu + eps * std # z = mu + sigma * eps
def decode(self, z):
h = F.relu(self.fc3(z))
return torch.sigmoid(self.fc4(h))
def forward(self, x):
mu, log_var = self.encode(x)
z = self.reparameterize(mu, log_var)
return self.decode(z), mu, log_var
5. 학습 루프 실행
데이터 로드부터 학습까지 전체 루프다. 에포크마다 Total Loss, Reconstruction Loss, KLD 세 값을 출력해서 학습이 잘 되고 있는지 확인하면 된다.
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
transform = transforms.ToTensor()
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = VAE().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(40):
model.train()
total_loss = 0
for data, _ in train_loader:
data = data.view(-1, 784).to(device)
optimizer.zero_grad()
recon, mu, log_var = model(data)
loss = vae_loss(recon, data, mu, log_var)
loss.backward()
optimizer.step()
total_loss += loss.item()
avg = total_loss / len(train_loader.dataset)
print(f"Epoch {epoch+1:02d}/40 | Loss: {avg:.2f}")
실행하면 아래처럼 에폭마다 Loss가 출력되고, 학습이 진행될수록 값이 점점 내려오는 걸 확인할 수 있다.
Epoch 01/40 | Loss: 164.33
Epoch 02/40 | Loss: 121.47
Epoch 03/40 | Loss: 114.40
Epoch 04/40 | Loss: 111.48
Epoch 05/40 | Loss: 109.77
Epoch 06/40 | Loss: 108.64
Epoch 07/40 | Loss: 107.73
Epoch 08/40 | Loss: 107.12
Epoch 09/40 | Loss: 106.60
Epoch 10/40 | Loss: 106.21
Epoch 11/40 | Loss: 105.84
Epoch 12/40 | Loss: 105.56
Epoch 13/40 | Loss: 105.30
...
Loss 추이를 그래프로 그려보면 세 항이 어떻게 변하는지 한눈에 볼 수 있다. 초반에 KLD가 살짝 올라가다가 안정화되는 패턴이 정상이다.
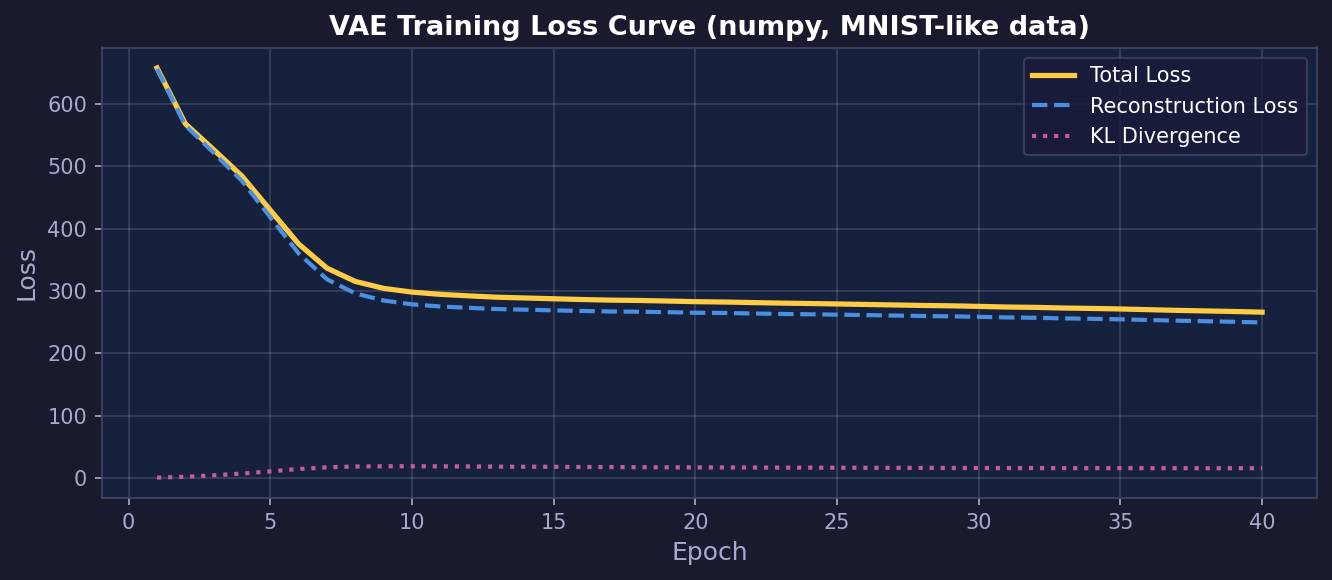
6. 이미지 생성 + 잠재 공간 보간
학습이 끝나면 잠재 공간에서 랜덤 샘플링으로 새 이미지를 생성할 수 있다.
표준 정규분포 N(0, I)에서 z를 뽑아서 디코더에 넣어주면 끝이다.
① 랜덤 샘플링으로 이미지 생성
model.eval()
with torch.no_grad():
z = torch.randn(16, 20).to(device)
generated = model.decode(z).cpu().view(-1, 1, 28, 28)
fig, axes = plt.subplots(2, 8, figsize=(16, 4))
for i, ax in enumerate(axes.flatten()):
ax.imshow(generated[i].squeeze(), cmap='gray')
ax.axis('off')
plt.suptitle("VAE Generated Images (MNIST)", fontsize=14)
plt.tight_layout()
plt.show()
결과:

② 잠재 공간 보간 (Latent Space Interpolation)
두 잠재 벡터 z1, z2 사이를 선형 보간하면 이미지가 자연스럽게 변환된다.
AE에서는 불가능하고 VAE에서만 제대로 작동하는 특성이다.
$$z(t) = (1-t) \cdot z_1 + t \cdot z_2, \quad t \in [0, 1]$$
model.eval()
with torch.no_grad():
latent_dim = model.fc_mu.out_features
z1 = torch.randn(1, latent_dim).to(device)
z2 = torch.randn(1, latent_dim).to(device)
steps = 10
imgs = []
for t in torch.linspace(0, 1, steps).to(device):
z_interp = (1 - t) * z1 + t * z2
img = model.decode(z_interp).cpu().view(28, 28)
imgs.append(img)
fig, axes = plt.subplots(1, steps, figsize=(20, 2.5))
for i, ax in enumerate(axes):
ax.imshow(imgs[i], cmap='gray')
ax.set_title(f"t={i/(steps-1):.1f}", fontsize=8)
ax.axis('off')
plt.suptitle("Latent Space Interpolation", fontsize=13)
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.show()
결과:

잠재 공간이 연속적이기 때문에 중간 t값들에서도 말이 되는 이미지가 나온다. 이게 VAE의 가장 직관적인 강점이다.
아래는 잠재 공간 전체 분포, 보간 경로, AE와의 밀도 차이를 한눈에 비교한 시각화다.

VAE는 이미지 품질보다 잠재 공간의 구조적 표현이 강점이라 이상 탐지(Anomaly Detection)나 데이터 증강에 많이 쓰인다. 그리고 최근에는 VAE와 Diffusion 모델을 합친 Latent Diffusion Model(LDM)이 Stable Diffusion의 핵심 구조가 됐다. 즉 VAE는 단독으로 쓰이는 것 이상으로 최신 생성 AI의 핵심 부품으로 자리잡고 있는 알고리즘이다.
VAE의 개념(ELBO, Reparameterization Trick, 잠재 공간)부터 PyTorch 구현, 이미지 생성, 보간까지 한 번에 정리해봤다. 생성 AI를 공부할 때 VAE를 먼저 이해하면 이후 VQVAE, Latent Diffusion, Stable Diffusion 구조 이해가 훨씬 수월해진다. 이상 끝! 🎨