모델을 다 만들고 나면 결국 하나로 귀결된다. "이 모델 진짜 좋은 모델 맞을까?"
처음엔 accuracy 하나만 보면 된다고 생각했지만, 데이터가 불균형한 상황에서는 accuracy가 99%여도 전혀 쓸모없는 모델일 수 있다. 회귀든 분류든, 상황에 맞는 지표를 골라 써야 비로소 모델의 성능을 제대로 판단할 수 있다. 이번 글에서는 회귀 지표 5가지 + 분류 지표 9가지, 총 14가지 평가 지표를 수식부터 코드까지 한 번에 정리해보았다. 레츠꼬 📊
1. 평가 지표 분류 한눈에 보기
모델의 목적이 다르면 평가 방식도 달라진다. 크게 회귀(Regression)와 분류(Classification)로 나뉘고, 각각 쓰이는 지표가 완전히 다르다.
| Task 유형 | 주요 지표 | 예시 문제 |
| 회귀 | MAE, RMSE, MAPE, R², Huber Loss | 집값 예측, 주가 예측, 기온 예측 |
| 분류 | Accuracy, F1, AUC-ROC, Log Loss, MCC, Cohen's Kappa, Top-K Accuracy | 스팸 분류, 암 진단, 이미지 분류 |
글 마지막에 14가지 지표를 한눈에 비교하는 치트시트도 첨부해뒀으니 참고하면 된다.
2. 회귀(Regression) 평가 지표
회귀 모델은 연속적인 숫자를 예측한다. 평가의 핵심은 예측값과 실제값의 차이(오차)를 어떻게 수치화하느냐이다.
① MAE (Mean Absolute Error)
오차의 절댓값을 평균 낸 값. 가장 직관적인 지표로, "평균적으로 얼마나 틀렸냐"를 원래 단위로 그대로 보여준다.
이상치(outlier)에 상대적으로 강건하다는 게 장점이다.
$$ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| $$
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_pred)
print(f"MAE: {mae:.4f}")
② RMSE (Root Mean Squared Error)
오차를 제곱한 뒤 평균 내고 루트를 씌운 값. 오차를 제곱하기 때문에 큰 오차에 더 강한 패널티를 부여한다.
이상치가 있거나 큰 오차가 치명적인 문제에서 선호되고, Kaggle 회귀 대회 기본 지표로 자주 쓰인다.
$$ \text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} $$
from sklearn.metrics import mean_squared_error
import numpy as np
rmse = np.sqrt(mean_squared_error(y_true, y_pred))
print(f"RMSE: {rmse:.4f}")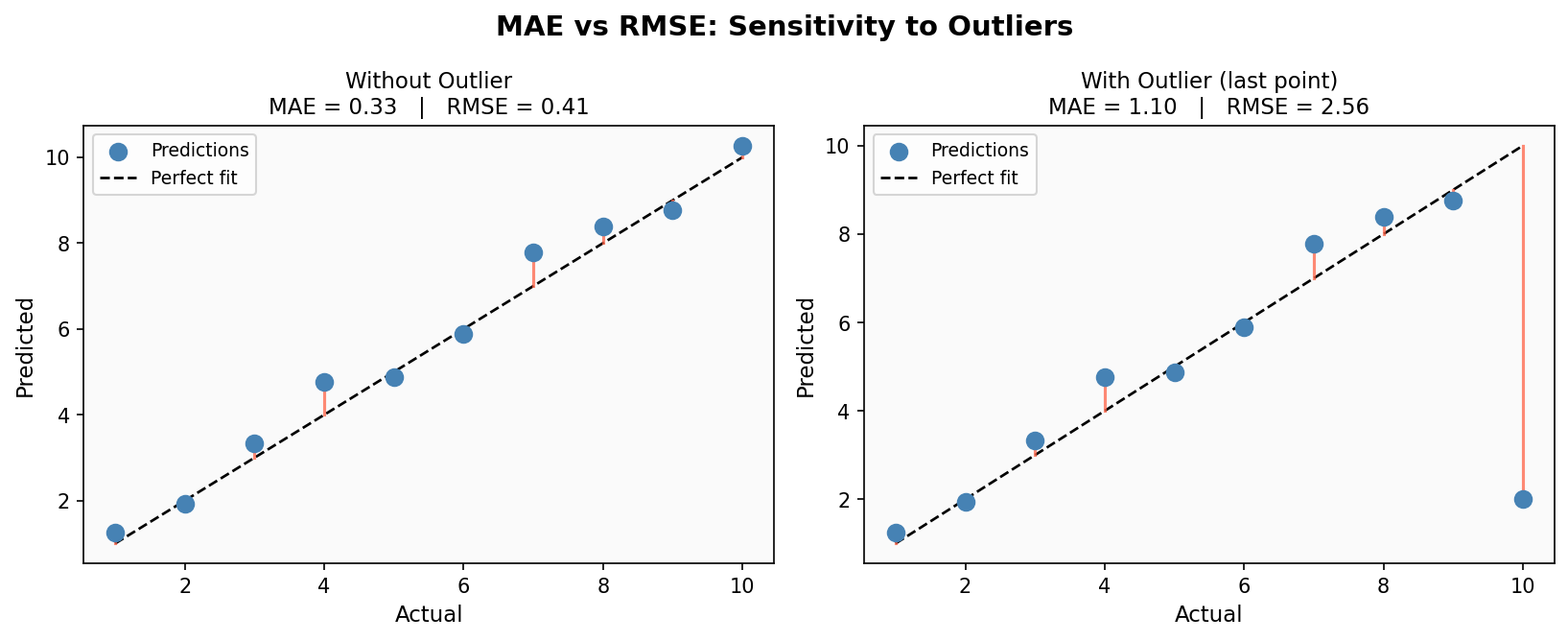
이미지를 보면 이상치가 생겼을 때 RMSE가 MAE보다 훨씬 크게 튀는 걸 확인할 수 있다. 이상치를 강하게 반영하고 싶으면 RMSE, 무시하고 싶으면 MAE를 쓰면 된다.
③ MAPE (Mean Absolute Percentage Error)
오차를 비율(%)로 표현한 지표. "평균적으로 몇 % 틀렸냐"를 바로 알 수 있어서 비즈니스 보고에서 매우 자주 쓰인다.
단, 실제값이 0에 가까우면 분모가 0에 수렴해서 발산한다는 치명적인 단점이 있다. 매출 예측, 수요 예측처럼 0이 없는 데이터에 쓰는 게 좋다.
$$ \text{MAPE} = \frac{1}{n} \sum_{i=1}^{n} \left| \frac{y_i - \hat{y}_i}{y_i} \right| \times 100 $$
import numpy as np
def mape(y_true, y_pred):
y_true, y_pred = np.array(y_true), np.array(y_pred)
return np.mean(np.abs((y_true - y_pred) / y_true)) * 100
print(f"MAPE: {mape(y_true, y_pred):.2f}%")
④ R² (결정계수, R-squared)
모델이 데이터의 분산을 얼마나 잘 설명하는지 나타내는 지표. 1에 가까울수록 좋고, 0이면 그냥 평균값으로 예측하는 것과 동일한 수준이다. 음수가 나오면 평균 예측보다도 못한 모델이라는 뜻이다.
$$ R^2 = 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y}_i)^2}{\sum_{i=1}^{n}(y_i - \bar{y})^2} = 1 - \frac{SS_{res}}{SS_{tot}} $$
한 가지 중요한 함정이 있다. R²는 변수를 무조건 추가할수록 값이 올라간다. 쓸모없는 변수를 넣어도 R²는 절대 줄어들지 않는다.
그래서 변수 수를 패널티로 반영한 Adjusted R²를 함께 확인해야 한다.
$$ \text{Adjusted } R^2 = 1 - \frac{(1 - R^2)(n - 1)}{n - p - 1} $$
여기서 n은 샘플 수, p는 독립변수(feature) 수다. 변수가 늘어날수록 분모가 작아져서 패널티를 부여하는 구조.
from sklearn.metrics import r2_score
r2 = r2_score(y_true, y_pred)
# Adjusted R²
n, p = len(y_true), X.shape[1]
adj_r2 = 1 - (1 - r2) * (n - 1) / (n - p - 1)
print(f"R²: {r2:.4f}, Adjusted R²: {adj_r2:.4f}")

⑤ Huber Loss
MAE와 MSE의 장점만 합친 하이브리드 손실 함수다.
오차가 임계값 δ(delta) 이하일 때는 MSE처럼 부드럽게 미분 가능하고, δ를 초과하면 MAE처럼 선형 증가로 이상치 영향을 제한한다.
$$ L_\delta(e) = \begin{cases} \dfrac{1}{2}e^2 & \text{if } |e| \leq \delta \\ \delta\left(|e| - \dfrac{\delta}{2}\right) & \text{otherwise} \end{cases} $$
여기서 e = y − ŷ, δ는 하이퍼파라미터로 직접 설정한다. δ가 클수록 MSE에 가까워지고, 작을수록 MAE에 가까워진다.
from sklearn.linear_model import HuberRegressor
model = HuberRegressor(epsilon=1.35) # epsilon이 delta 역할
model.fit(X_train, y_train)

3. 분류(Classification) 평가 지표 기초 — Confusion Matrix
분류 지표 대부분은 Confusion Matrix(혼동 행렬)에서 파생된다. 여기서 나오는 4가지 값(TP, FP, TN, FN)을 이해하면 이후 지표들은 전부 자연스럽게 따라온다.
| 약어 | 풀네임 | 의미 |
| TP | True Positive | 실제 Positive → 모델도 Positive 예측 (정답) |
| FP | False Positive | 실제 Negative → 모델이 Positive 예측 (오보) |
| FN | False Negative | 실제 Positive → 모델이 Negative 예측 (누락) |
| TN | True Negative | 실제 Negative → 모델도 Negative 예측 (정답) |

4. Accuracy / Balanced Accuracy
Accuracy는 가장 단순한 분류 지표다. 전체 예측 중 맞춘 비율.
$$ \text{Accuracy} = \frac{TP + TN}{TP + FP + FN + TN} $$
문제는 데이터 불균형이 있을 때다. 예를 들어 암 환자가 1%, 정상인이 99%라면, 그냥 "다 정상"이라고만 예측해도 Accuracy = 99%가 나온다. 이를 보완한 게 Balanced Accuracy다. 각 클래스별 Recall을 평균 내는 방식이라, 클래스 불균형에 영향을 덜 받는다.
$$ \text{Balanced Accuracy} = \frac{1}{K} \sum_{k=1}^{K} \frac{TP_k}{TP_k + FN_k} $$
K는 클래스 수. 이진 분류에선 K=2이므로 결국 (Sensitivity + Specificity) / 2와 동일하다.
from sklearn.metrics import accuracy_score, balanced_accuracy_score
acc = accuracy_score(y_true, y_pred)
bal_acc = balanced_accuracy_score(y_true, y_pred)
print(f"Accuracy: {acc:.4f}, Balanced Accuracy: {bal_acc:.4f}")
5. Precision / Recall / F1-Score
Precision(정밀도)은 "Positive라고 예측한 것 중 진짜 Positive의 비율"이다. 스팸 필터처럼 FP(정상을 스팸으로 분류)가 치명적인 경우에 중요하다.
$$ \text{Precision} = \frac{TP}{TP + FP} $$
Recall(재현율)은 "실제 Positive 중에서 모델이 잡아낸 비율"이다. 암 진단처럼 FN(환자를 정상으로 놓침)이 치명적인 경우에 중요하다.
$$ \text{Recall} = \frac{TP}{TP + FN} $$
그런데 Precision과 Recall은 트레이드오프 관계다. 임계값을 낮추면 Recall은 올라가지만 Precision은 내려간다. 이 둘을 균형 있게 잡아주는 게 F1-Score다. F1은 두 지표의 조화평균으로, 어느 하나가 낮으면 F1도 확 낮아지기 때문에 둘 다 고루 높아야 좋은 점수를 받는다.
$$ \text{F1} = \frac{2 \times \text{Precision} \times \text{Recall}}{\text{Precision} + \text{Recall}} = \frac{2 \cdot TP}{2 \cdot TP + FP + FN} $$
Precision과 Recall의 중요도가 다를 때는 F-beta Score를 쓴다. β > 1이면 Recall에 더 가중치, β < 1이면 Precision에 더 가중치를 둔다.
$$ F_\beta = (1 + \beta^2) \cdot \frac{\text{Precision} \times \text{Recall}}{\beta^2 \cdot \text{Precision} + \text{Recall}} $$
from sklearn.metrics import classification_report, fbeta_score
print(classification_report(y_true, y_pred))
# F2-Score: Recall을 2배 중요하게
f2 = fbeta_score(y_true, y_pred, beta=2)
print(f"F2-Score: {f2:.4f}")
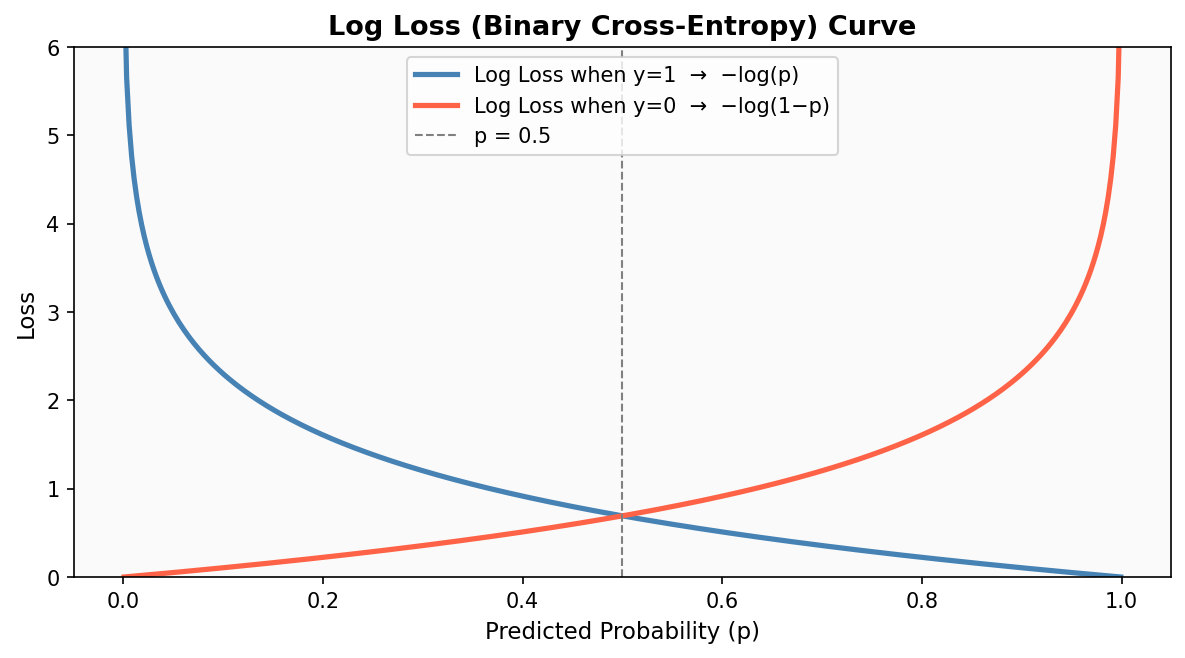
6. Log Loss (Binary Cross-Entropy)
Log Loss는 모델이 출력한 확률값 자체의 품질을 평가한다. 단순히 맞췄냐/틀렸냐가 아니라, 얼마나 확신을 갖고 맞췄냐까지 반영한다.
예를 들어 p=0.51로 간신히 맞춘 모델과 p=0.99로 확신하며 맞춘 모델은 Accuracy는 같지만 Log Loss는 다르다.
$$ \text{Log Loss} = -\frac{1}{n}\sum_{i=1}^{n}\left[y_i \log(\hat{p}_i) + (1 - y_i)\log(1 - \hat{p}_i)\right] $$
여기서 ŷᵢ는 Positive 클래스에 대한 예측 확률이다.
log(0)은 -∞이기 때문에, 확률을 0 또는 1로 완전히 확신했다가 틀리면 Loss가 폭발한다. 캘리브레이션이 잘 된 확률 모델일수록 Log Loss가 낮다.
from sklearn.metrics import log_loss
# y_prob: predict_proba()로 얻은 확률값
ll = log_loss(y_true, y_prob)
print(f"Log Loss: {ll:.4f}")
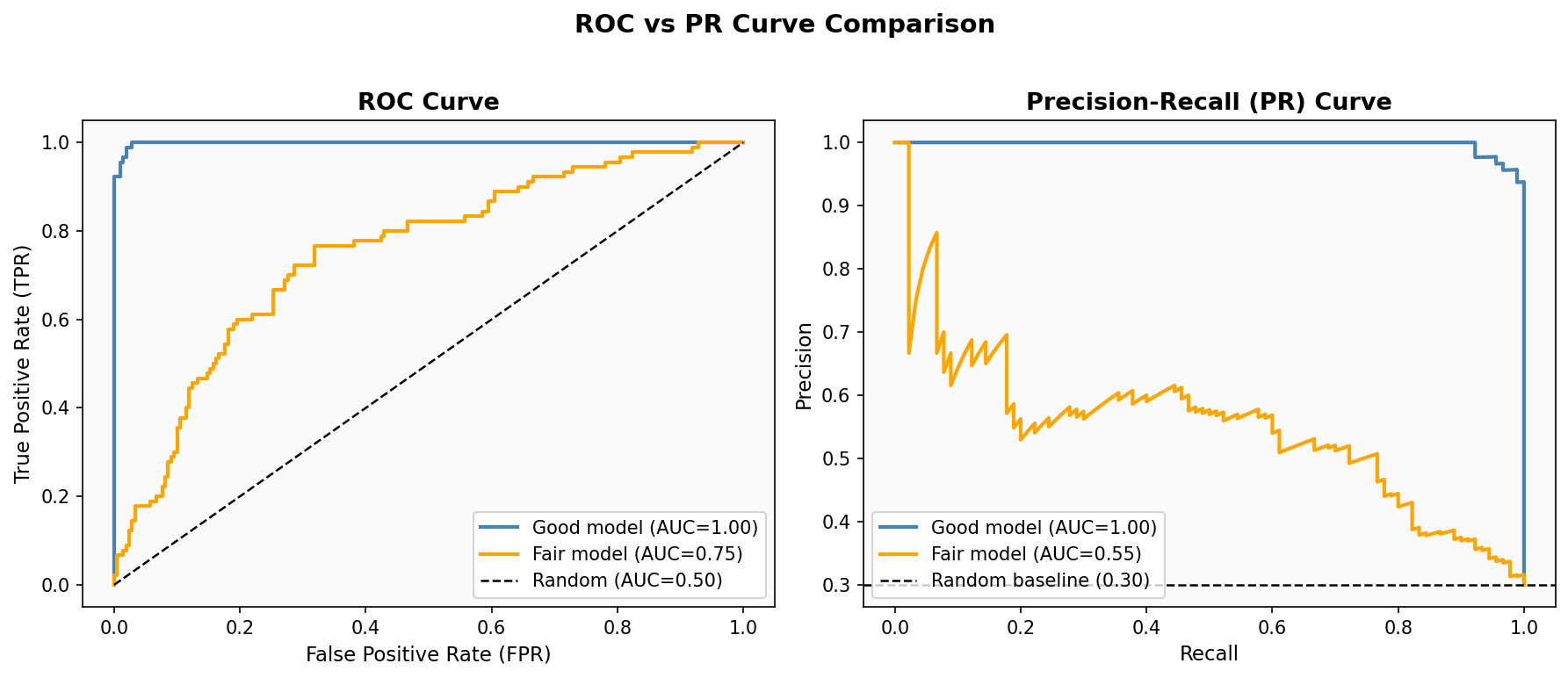
7. AUC-ROC / PR Curve
분류 모델은 내부적으로 확률을 출력하고 임계값 기준으로 클래스를 결정한다. 그런데 임계값을 어떻게 잡느냐에 따라 Precision/Recall이 달라지기 때문에, 임계값과 무관한 종합 평가가 필요하다.
ROC Curve는 임계값을 0→1로 변화시키면서 FPR(False Positive Rate)과 TPR(Recall)의 관계를 그린 곡선이다.
AUC는 이 곡선 아래 넓이로, 0.5이면 랜덤 예측 수준, 1.0이면 완벽한 모델이다.
$$ \text{FPR} = \frac{FP}{FP + TN}, \quad \text{TPR} = \frac{TP}{TP + FN} $$ $$ \text{AUC-ROC} = \int_0^1 \text{TPR}(\text{FPR})\, d(\text{FPR}) $$
단, 클래스 불균형이 심할 때는 ROC가 misleading하다. 음성 클래스가 압도적으로 많으면 FPR이 작게 유지되기 쉬워서 AUC가 과대평가되기 때문. 이럴 때는 PR Curve(Precision-Recall Curve)가 더 적합하다. X축이 Recall, Y축이 Precision이고, 소수 클래스(minority class)에 집중한 평가가 가능하다.
from sklearn.metrics import roc_auc_score, average_precision_score
auc_roc = roc_auc_score(y_true, y_prob)
pr_auc = average_precision_score(y_true, y_prob) # PR-AUC
print(f"AUC-ROC: {auc_roc:.4f}")
print(f"PR-AUC: {pr_auc:.4f}")
8. MCC (Matthews Correlation Coefficient)
MCC는 클래스 불균형이 극심한 상황에서도 신뢰할 수 있는 지표다. Confusion Matrix의 네 값을 모두 활용해서 계산하기 때문에, 불균형 데이터에서도 우연히 좋은 점수를 받기 어렵다.
$$ \text{MCC} = \frac{TP \cdot TN - FP \cdot FN}{\sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}} $$
범위는 -1 ~ +1이다. +1이면 완벽한 예측, 0이면 랜덤 예측, -1이면 완전히 반대로 예측하는 것.
F1이 Positive 클래스만 고려하는 반면, MCC는 TP/FP/TN/FN을 전부 반영해서 더 균형 잡힌 평가를 한다. 생물정보학, 의료 분야에서 자주 사용된다.
from sklearn.metrics import matthews_corrcoef
mcc = matthews_corrcoef(y_true, y_pred)
print(f"MCC: {mcc:.4f}")
9. Cohen's Kappa
Cohen's Kappa는 우연에 의한 일치를 제거한 후 모델 성능을 평가한다. 단순 Accuracy는 클래스 분포만 봐도 맞출 수 있는 "우연" 성능을 포함하지만, Kappa는 그걸 빼준다.
$$ \kappa = \frac{p_o - p_e}{1 - p_e} $$
여기서 p_o는 실제 관측된 일치율(Accuracy), p_e는 우연히 일치할 확률이다.
범위는 -1 ~ 1이고, 보통 0.8 이상이면 거의 완벽한 일치, 0.6~0.8이면 양호한 수준으로 해석한다.
여러 클래스가 있는 다중 분류 문제, 특히 전문가 간 평가 일치도 측정에 자주 쓰인다.
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y_true, y_pred)
print(f"Cohen's Kappa: {kappa:.4f}")
10. Top-K Accuracy
Top-K Accuracy는 다중 분류(multi-class) 문제에서 모델이 예측한 확률 상위 K개 중에 정답이 포함되는지를 기준으로 평가한다.
클래스 수가 매우 많을 때 유용하다. 대표적인 예가 ImageNet — 1000개 클래스를 분류하는 모델은 Top-1 Accuracy보다 Top-5 Accuracy를 기본 지표로 사용한다.
$$ \text{Top-K Accuracy} = \frac{1}{n}\sum_{i=1}^{n} \mathbf{1}\left[y_i \in \text{top-K}(\hat{p}_i)\right] $$
예를 들어 Top-5 Accuracy = 0.95라면, 모델이 예측한 확률 상위 5개 클래스 안에 정답이 들어가는 비율이 95%라는 의미다.
import numpy as np
def top_k_accuracy(y_true, y_prob, k=5):
top_k = np.argsort(y_prob, axis=1)[:, -k:]
return np.mean([y_true[i] in top_k[i] for i in range(len(y_true))])
# sklearn 버전 (1.0+)
from sklearn.metrics import top_k_accuracy_score
score = top_k_accuracy_score(y_true, y_prob, k=5)
print(f"Top-5 Accuracy: {score:.4f}")
11. Cross-Entropy
Cross-Entropy는 Log Loss를 다중 클래스(multi-class)로 확장한 개념이다. 딥러닝 분류 모델에서 가장 많이 쓰이는 손실 함수이기도 하다.
이진 분류에서는 Binary Cross-Entropy = Log Loss와 동일하다.
$$ \text{Categorical Cross-Entropy} = -\frac{1}{n}\sum_{i=1}^{n}\sum_{k=1}^{K} y_{ik} \log(\hat{p}_{ik}) $$
여기서 y_ik는 샘플 i가 클래스 k이면 1, 아니면 0 (one-hot encoding), p̂_ik는 클래스 k에 대한 예측 확률이다.
결국 모델이 정답 클래스에 얼마나 높은 확률을 부여했는지를 평가하는 것. 확률을 0에 가깝게 예측했다가 틀리면 log(0) → -∞ 이기 때문에 Loss가 폭발한다.
import torch.nn as nn
# PyTorch
criterion = nn.CrossEntropyLoss()
loss = criterion(logits, labels) # logits: (N, C), labels: (N,)
# sklearn (multi-class log loss와 동일)
from sklearn.metrics import log_loss
ce = log_loss(y_true, y_prob) # y_prob: (N, C) 확률 행렬
print(f"Cross-Entropy: {ce:.4f}")
12. 지표 선택 가이드 — 언제 뭘 써야 할까?
지표를 다 알아도 막상 선택이 가장 어렵다. 상황별로 정리하면 아래와 같다.
| 상황 | 추천 지표 | 이유 |
| 이상치 있는 회귀 | MAE, Huber Loss | 큰 오차를 제곱하지 않아 이상치에 강건 |
| 큰 오차에 패널티가 중요한 회귀 | RMSE | 제곱 항이 큰 오차를 강하게 반영 |
| 비즈니스 보고용 회귀 | MAPE | %로 설명 가능, 직관적 |
| 설명력 중심 회귀 | Adjusted R² | 변수 수 패널티로 과적합 방지 |
| 균형 잡힌 데이터 분류 | Accuracy | 단순하고 직관적 |
| 불균형 데이터 분류 | F1, Balanced Accuracy, MCC | Accuracy의 함정 회피 |
| FP가 치명적인 경우 (스팸 필터) | Precision 우선 | 정상 메일을 스팸으로 오분류 방지 |
| FN이 치명적인 경우 (암 진단) | Recall 우선 | 환자를 정상으로 놓치면 안 됨 |
| 확률 캘리브레이션 평가 | Log Loss, Cross-Entropy | 확신도까지 포함한 평가 |
| 임계값 무관 모델 비교 | AUC-ROC | threshold 없이 공평하게 비교 |
| 소수 클래스 집중 평가 | PR-AUC | 불균형 데이터에서 ROC보다 정직 |
| 클래스 수 많은 분류 | Top-K Accuracy | 순위 기반 평가, ImageNet 등 |
| 우연 보정 필요한 다중 분류 | Cohen's Kappa | 랜덤 일치율을 제거하여 보정 |
지표는 정답이 없다. 도메인과 비즈니스 목적에 따라 달라지며 실무에서는 항상 여러 지표를 함께 보는 게 좋다.

회귀 지표(MAE, RMSE, MAPE, R², Huber Loss)부터 분류 지표(Accuracy, F1, Log Loss, AUC-ROC, PR Curve, MCC, Cohen's Kappa, Top-K Accuracy, Cross-Entropy)까지 총 14가지를 수식과 코드로 정리해봤다.
다음 글에서는 실제 불균형 데이터셋에 이 지표들을 직접 적용해서 모델을 비교하고 개선하는 과정을 다뤄볼 예정이다.
이상 끝! 📊