공간데이터에 OLS 회귀분석을 적용하면, 잔차가 독립적이라는 가정이 자주 깨진다. 잔차를 지도 위에 시각화하면 유사한 값들이 공간적으로 군집하는 패턴이 나타나기 때문이다. 이는 전통적인 통계 모델이 공간적 의존성을 충분히 반영하지 못한다는 신호다.
공간통계는 그 불편함에서 출발한다. 이번 1편에서는 왜 OLS가 공간에서 한계를 가지는지, 그걸 진단하는 공간자기상관과 Moran's I, 분석의 핵심 재료인 공간가중행렬(W), 그리고 공간 구조를 모형에 반영하는 SLM과 SEM까지 정리해본다. 레츠꼬 📐
1. OLS(Ordinary Least Squares)가 놓치는 공간 의존성
OLS(Ordinary Least Squares)는 회귀분석의 기본 중의 기본이다. 잔차의 제곱합을 최소화하는 방식으로 회귀계수를 추정하는데, 이게 제대로 작동하려면 몇 가지 가정이 반드시 충족되어야 한다. 그 중에서도 가장 핵심이 되는 게 오차항의 독립성(Independence of Errors)이다. 한 관측값의 잔차가 다른 관측값의 잔차와 관련이 없어야 한다는 것.
그런데 공간데이터는 태생적으로 이 가정을 위반한다. 지리학의 제1법칙, Tobler의 법칙(Tobler's First Law of Geography)에서는 다음과 같이 설명한다.
"모든 것은 다른 모든 것과 관련되어 있지만, 가까운 것은 먼 것보다 더 관련되어 있다."
— Waldo Tobler, 1970
서울 강남구의 집값은 옆 동네 서초구 집값과 연관이 깊다. 부산 해운대의 기온은 옆 동네 기온과 비슷하다. 공간적으로 가까운 관측값들은 서로 닮아있다는 게 바로 공간자기상관(Spatial Autocorrelation)이다.
OLS로 공간자기상관이 있는 데이터를 분석하면 구체적으로 세 가지 문제가 생긴다.
① 표준오차(Standard Error)가 과소추정된다
잔차들이 독립이 아니라 서로 비슷한 값을 가지는 경우, 실제로 갖고 있는 정보량이 표본 크기보다 훨씬 적다. OLS는 이를 모르고 표본 크기만큼 정보가 있다고 가정하니, 표준오차가 작게 나오고 통계적 유의성이 실제보다 부풀려진다. 거짓 양성(False Positive)이 늘어나는 것이다.
② 회귀계수 추정이 비효율적(Inefficient)이 된다
계수 자체는 불편추정량(Unbiased)일 수 있지만, 공간구조를 무시하면 최소분산 추정량(BLUE, Best Linear Unbiased Estimator)이 아니게 된다. Gauss-Markov 정리의 "Best" 조건이 깨지는 것이다. 즉 같은 데이터로 더 좋은 추정을 할 수 있는데 못 하고 있는 상황이 된다.
③ 잔차에 공간적 패턴이 남는다
OLS 잔차를 지도에 뿌렸을 때 특정 지역에 비슷한 잔차 값들이 몰려 있다면, 그건 모형이 설명하지 못한 공간적 구조가 있다는 신호다. 중요한 공간 변수를 누락했거나, 모형 구조 자체를 잘못 설정한 것이다. 이 패턴을 수치로 측정하는 게 바로 다음 섹션에서 다룰 Moran's I다.

결국 OLS가 공간데이터에 맞지 이유는 단순하다. 공간데이터는 독립이 아니라 의존적이기 때문이다. 이걸 무시하면 통계적 추론 자체가 흔들린다. 그래서 공간통계가 필요한 거다.
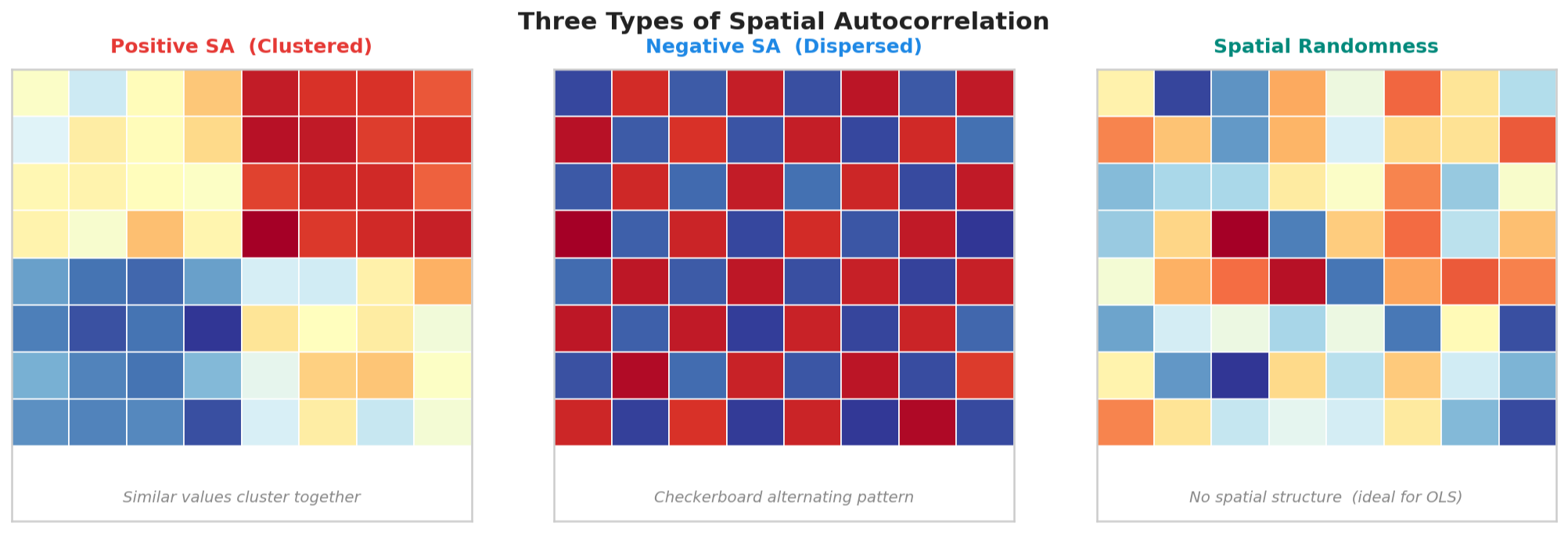
2. 공간자기상관(Spatial Autocorrelation)의 개념
공간자기상관(Spatial Autocorrelation)은 어떤 변수가 공간적으로 얼마나 유사하게 분포하는지를 나타내는 개념이다. 일반 통계의 자기상관(Autocorrelation)이 "과거가 현재와 얼마나 관련 있냐"를 보는 거라면, 공간자기상관은 공간 축에서 "이웃이 나와 얼마나 닮아있냐"를 보는 것이다.
공간자기상관은 크게 세 가지 경우로 나뉜다:
| 유형 | 의미 | 예시 |
| 양의 공간자기상관 (Positive SA) |
비슷한 값들이 공간적으로 뭉쳐있음. 높은 값 옆에 높은 값, 낮은 값 옆에 낮은 값. | 집값 분포, 기온 분포, 소득 수준, 범죄율 클러스터 |
| 음의 공간자기상관 (Negative SA) |
다른 값들이 공간적으로 교차 분포. 체스판처럼 고-저-고-저 패턴. | 경쟁 관계에 있는 시설 분포 (마트, 주유소 등) |
| 공간적 무작위성 (Spatial Randomness) |
공간 패턴 없음. 완전 무작위 분포. 위치와 값 사이에 아무 관련이 없음. | 동전 던지기처럼 위치와 무관. |
현실에서 가장 흔한 건 양의 공간자기상관이다. 비슷한 자연환경, 비슷한 용도지역, 비슷한 근린을 가진 지역들이 공간적으로 붙어있는 경우가 많기 때문이다. 경제학적으로는 집적 효과(Agglomeration Effect)나 파급 효과(Spillover Effect)가 이런 공간적 유사성을 만들어낸다.
음의 공간자기상관은 상대적으로 드물지만, 경쟁하는 시설들이 서로 거리를 두고 배치되는 경우나 토지이용이 교차하는 패턴에서 나타난다. 중요한 건 이 패턴을 수치로 측정하는 것인데, 여기서 Moran's I가 등장한다.
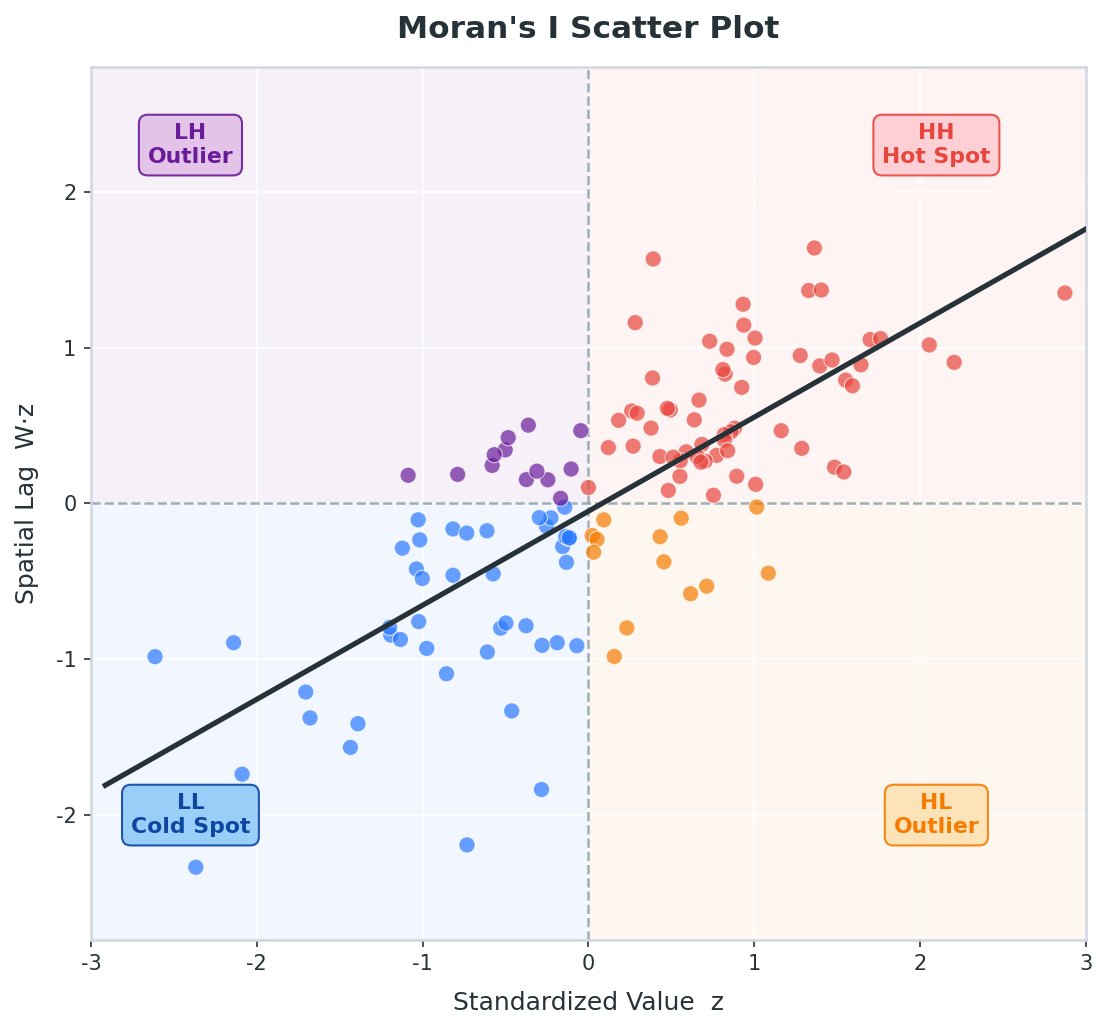
3. Moran's I — 전역 공간자기상관 측정
Moran's I는 1950년 Patrick Alfred Pierce Moran이 제안한 전역적(Global) 공간자기상관 지표다. 값의 범위는 이론적으로 -1에서 +1이고, 해석은 아래와 같이 하면 된다:
| Moran's I 값 | 해석 |
| +1에 가까울수록 | 강한 양의 공간자기상관. 비슷한 값들이 강하게 군집. (Positive SA) |
| 기대값 E(I) ≈ 0 | 공간적 무작위성. 정확한 기대값은 -1/(n-1)이지만 n이 크면 0에 수렴. (Spatial Randomness) |
| -1에 가까울수록 | 강한 음의 공간자기상관. 다른 값들이 교차 배치. (Negative SA) |
수식은 이렇다. 겁먹을 필요 없이 구조만 이해하면 된다:
$$
I = \frac{N}{S_0}
\cdot
\frac{\sum_i \sum_j w_{ij}(x_i - \bar{x})(x_j - \bar{x})}
{\sum_i (x_i - \bar{x})^2}
$$
분자를 보면 wᵢⱼ(xᵢ - x̄)(xⱼ - x̄)라는 항이 있다. wᵢⱼ는 i와 j가 이웃이면 1(아니면 0), (xᵢ - x̄)와 (xⱼ - x̄)는 각각의 평균 편차다.
이웃한 두 지역이 평균보다 둘 다 높으면(++ = 양수), 또는 둘 다 낮으면(-- = 양수) 분자가 커진다 → 양의 공간자기상관. 반대로 이웃끼리 서로 다른 방향(+- = 음수)이면 분자가 작아진다 → 음의 공간자기상관. 결국 이웃끼리 얼마나 함께 움직이냐를 측정하는 것이다. 분모는 전체 분산으로 정규화하는 역할을 한다.
Moran's I를 시각화한 게 Moran Scatter Plot이다. X축은 표준화된 변수값(z), Y축은 이웃들의 가중 평균값인 공간 래그(Wz)인 산점도인데, 이 산점도의 회귀선 기울기가 Moran's I 값이 된다. 4분면으로 나뉘는 구조 - HH, LL, HL, LH - 는 2편에서 다룰 LISA 분류에서 설명할 예정이다.
import libpysal
from esda.moran import Moran
# 1. 공간가중행렬 생성 (Queen contiguity, 행 표준화)
w = libpysal.weights.Queen.from_dataframe(gdf)
w.transform = 'r'
# 2. Moran's I 계산
moran = Moran(gdf['변수명'], w)
print(f"Moran's I: {moran.I:.4f}")
print(f"기대값 E(I): {moran.EI:.4f}") # ≈ -1/(n-1)
print(f"Z-score: {moran.z_norm:.4f}")
print(f"p-value (정규분포 가정): {moran.p_norm:.4f}")
print(f"p-value (MC 시뮬레이션): {moran.p_sim:.4f}") # 더 신뢰도 높음
결과 해석할 때는 Moran's I 값과 p-value를 반드시 함께 봐야 한다. I가 높더라도 p-value가 0.05보다 크면 통계적으로 유의하지 않다. p-value는 정규분포 가정 기반(p_norm)보다 Monte Carlo 시뮬레이션 기반(p_sim)이 더 신뢰도가 높으니, 특히 표본이 작거나 분포가 정규성을 따르지 않을 때는 반드시 p_sim을 쓸 것!
Moran's I의 한계도 알아둬야 한다. 전역(Global) 통계이기 때문에 연구 지역 전체에 대한 하나의 요약값만 준다. 어떤 지역은 핫스팟이고 어떤 지역은 콜드스팟이고 어떤 지역은 이상값인데, 그게 전부 뭉개져서 숫자 하나로 나온다. 전체적으로 "공간자기상관이 있다/없다"는 판단엔 유용하지만, 어디에 어떻게 있는지는 알 수 없다. 그럴때는 로컬(Local) 자기상관을 확인할 수 있는 LISA와 Getis-Ord Gi* 를 사용하면 된다. (2편에서 다룰 예정)
4. 공간가중행렬(Spatial Weights Matrix, W) 만들기
지금까지 나온 Moran's I, 그리고 뒤에서 다룰 공간회귀 모형들의 공통 핵심 재료?가 있다. 바로 공간가중행렬(Spatial Weights Matrix, W)이다. "어떤 지역을 이웃으로 볼 것인가"와 "이웃 간 영향력의 크기를 어떻게 정의할 것인가"를 수치로 표현한 N×N 행렬이다.
W[i][j]는 지역 i와 j의 이웃 관계를 나타낸다. 이웃이면 1(또는 거리에 비례한 가중치), 아니면 0. 어떤 방식으로 W를 정의하느냐에 따라 분석 결과가 크게 달라질 수 있어 데이터의 성격과 연구 질문에 맞게 신중하게 선택해야 한다.
| 방식 | 설명 | 적합한 상황 |
| Rook Contiguity | 경계선(edge)을 공유하는 지역만 이웃으로 정의. 상하좌우 4방향. | 격자형 행정구역 폴리곤 |
| Queen Contiguity | 경계선 + 꼭짓점(corner)을 공유하는 지역까지 이웃으로 정의. 8방향. 가장 일반적으로 사용. | 행정구역 폴리곤 (대부분의 경우 권장) |
| K-Nearest Neighbors | 거리 기준 가장 가까운 K개를 이웃으로 정의. 모든 지역이 동일한 수의 이웃을 가짐. | 포인트 데이터, 이웃 수를 균등하게 하고 싶을 때 |
| Distance Band | 일정 임계 거리(threshold) 안에 있는 모든 지역을 이웃으로 정의. | 명확한 거리 영향권이 있을 때 |
| Inverse Distance | 거리의 역수(1/d 또는 1/d²)로 가중치 부여. 멀수록 영향력이 점진적으로 감소. | 거리에 따른 연속적 영향력 감소를 가정할 때 |

import libpysal
# 1. Queen Contiguity (가장 일반적)
w_queen = libpysal.weights.Queen.from_dataframe(gdf)
# 2. Rook Contiguity
w_rook = libpysal.weights.Rook.from_dataframe(gdf)
# 3. K-Nearest Neighbors (K=5)
w_knn = libpysal.weights.KNN.from_dataframe(gdf, k=5)
# 4. Distance Band (좌표가 미터 단위라면 1km 이내)
w_dist = libpysal.weights.DistanceBand.from_dataframe(gdf, threshold=1000)
# - 행 표준화 (Row Standardization) -
# 각 행의 합이 1이 되도록 → 이웃 수가 달라도 공간래그 비교 가능
w_queen.transform = 'r'
# 기본 정보 확인
print(f"지역 수: {w_queen.n}")
print(f"최소 이웃 수: {min(w_queen.cardinalities.values())}")
print(f"최대 이웃 수: {max(w_queen.cardinalities.values())}")
print(f"고립 지역(섬): {len(w_queen.islands)}개") # 이웃 없는 지역 반드시 확인!
행 표준화(Row Standardization)는 거의 항상 해주는 게 좋다. 이웃 수가 지역마다 다를 때(섬처럼 이웃이 2개뿐인 지역과 내륙 중심부처럼 이웃이 8개인 지역이 섞여 있을 때) 표준화 없이 쓰면 이웃이 많은 지역의 공간 래그 값이 과대평가된다. 행 표준화를 하면 각 이웃에게 1/k의 균등 가중치를 부여하는 셈이 된다.
한 가지 꼭 챙겨야 할 것: 고립 지역(Island)이 있으면 분석에 문제가 생긴다. 이웃이 아예 없는 지역은 공간가중행렬에서 해당 행이 모두 0이 돼서 공간 Lag 계산이 불가능하다. 실제 분석 전에 w.islands로 반드시 확인하고, 있으면 KNN으로 강제 연결하거나 해당 지역을 어떻게 처리할지 고민해보아야 한다.
5. 공간시차모형(Spatial Lag Model, SLM)
이제 본격적인 공간회귀모형으로 넘어간다. 공간자기상관이 확인됐다면 그걸 그냥 무시하는 게 아니라 모형에 직접 반영해서 더 정확한 추정을 해야 한다. 공간회귀 모형은 크게 두 가지 SLM과 SEM 으로 나뉘는데, 공간자기상관이 어디서 발생하는지에 따라 선택이 달라진다.
첫 번째가 공간시차모형(Spatial Lag Model, SLM)이다. SAR(Spatial AutoRegressive Model)이라고도 불린다. 핵심 아이디어: 이웃 지역의 종속변수 값이 내 종속변수에 직접 영향을 준다는 것을 모형에 명시적으로 포함시킨다.
$$
\mathbf{y} = \rho \mathbf{W} \mathbf{y} + \mathbf{X} \boldsymbol{\beta} + \boldsymbol{\varepsilon}
$$
OLS 수식(y = Xβ + ε)에서 ρWy 항 하나가 추가된 것이다. Wy는 공간 래그(Spatial Lag) = W행렬로 가중 평균한 이웃들의 y값이다. ρ(rho)는 그 공간 파급 효과의 강도이다.
| 파라미터 | 의미 및 해석 |
| ρ (rho) | 공간 파급 효과의 강도. 양수이면 이웃의 높은 y값이 나의 y값을 끌어올림. 모형의 안정성을 위해 -1 < ρ < 1 범위 내에 있어야 함. |
| Wy | 공간 래그 — W행렬로 가중 평균한 이웃들의 종속변수값. 이걸 독립변수처럼 추가하는 셈. |
| β | 독립변수의 직접 효과. OLS의 β와 해석 방법이 다름 — 공간 피드백 효과가 포함돼 있어 직접+간접 효과를 분해해야 함. |
| ε | 오차항. SLM에서는 오차가 공간적으로 독립이라고 가정. |
SLM에서 중요한 점은 계수 해석 방식이 OLS와 다르다는 것이다. OLS에서 β는 단순히 X가 1 증가하면 y가 β 증가한다. 하지만 SLM에서는 한 지역의 X 변화가 그 지역의 y에 직접 영향을 주고(Direct Effect), 그것이 다시 이웃의 y를 통해 피드백되어 돌아오는 효과(Indirect Effect, 파급 효과)까지 발생한다. 따라서 직접 효과(Direct) + 간접 효과(Indirect) = 총 효과(Total)로 분해해서 봐야 한다.
from spreg import ML_Lag, OLS
# ── Step 1: OLS 먼저 돌리고 공간진단 통계 확인 ──
ols = OLS(
y = gdf[['종속변수']].values,
x = gdf[['독립변수1', '독립변수2']].values,
w = w_queen,
spat_diag = True, # LM-lag, LM-error, Robust LM 자동 계산
name_y = '종속변수',
name_x = ['독립변수1', '독립변수2'],
)
print(ols.summary)
# → 결과에서 LM-lag, LM-error p-value 확인 후 모형 선택
# ── Step 2: 공간시차모형 (SLM/SAR) 최대우도 추정 ──
slm = ML_Lag(
y = gdf[['종속변수']].values,
x = gdf[['독립변수1', '독립변수2']].values,
w = w_queen,
name_y = '종속변수',
name_x = ['독립변수1', '독립변수2'],
name_w = 'Queen',
name_ds = '데이터셋명'
)
print(slm.summary)
# 핵심 확인: rho 값·유의성, AIC가 OLS보다 낮은지
SLM은 실질적인 공간 파급 효과(spillover effect)가 이론적으로 기대될 때 적합하다. 예를 들어 인접 시군구의 공공투자가 내 지역 경제성장에 영향을 주는 경우, 옆 동네 집값 상승이 내 동네에 파급되는 경우 등. ρ가 양수이고 유의하다면 그 공간 파급이 데이터로 확인된 것이다.
6. 공간오차모형(Spatial Error Model, SEM)
두 번째 공간회귀 모형은 공간오차모형(Spatial Error Model, SEM)이다. SLM이 "이웃의 y값이 나의 y에 직접 영향을 준다"는 실질적 공간 의존성을 다뤘다면, SEM은 다른 관점에서 접근한다.
SEM의 핵심 아이디어: 모형에서 빠진 공간적 변수들(누락 변수)의 영향이 오차항에 공간자기상관 구조로 나타난다. 실질적인 공간 파급이 있다기보다는 우리가 모르는 공간적 요인이 있어서 오차가 공간적으로 연관되는 상황이다.
$$
\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \mathbf{u}, \quad
\mathbf{u} = \lambda \mathbf{W} \mathbf{u} + \boldsymbol{\varepsilon}
$$
오차 u 자체가 공간 Lag 구조(λWu)를 가진다. λ(람다)가 오차의 공간자기상관 강도다. λ가 크고 유의하다는 건 이웃의 오차가 나의 오차에 큰 영향을 준다는 것이고, 이는 공간적으로 누락된 변수가 있다는 신호다.
| 구분 | 공간시차모형 (SLM) | 공간오차모형 (SEM) |
| 공간 의존성의 위치 | 종속변수 y에 있음 (Wy 항) | 오차항 u에 있음 (Wu 항) |
| 핵심 가정 | 이웃 y값이 실질적으로 y에 영향 | 공간적 누락 변수가 오차에 반영됨 |
| 파급 효과 | 실질적 공간 파급 존재 (Spillover) | 공간 오차 구조 보정 (Nuisance) |
| β 해석 | 직접+간접 효과 분해 필요 | OLS처럼 직접 해석 가능 |
| 핵심 파라미터 | ρ (공간 파급 강도) | λ (오차의 공간 구조 강도) |
SEM은 OLS 계수의 효율성(Efficiency)을 회복시켜준다. SLM처럼 파급 효과를 추정하는 게 아니라, 공간적 오차 구조를 통제해서 β 추정을 더 정밀하게 만드는 것이다. SEM의 β는 OLS처럼 직접 해석할 수 있다는 장점이 있다.
from spreg import ML_Error
# 공간오차모형 (SEM) 최대우도 추정
sem = ML_Error(
y = gdf[['종속변수']].values,
x = gdf[['독립변수1', '독립변수2']].values,
w = w_queen,
name_y = '종속변수',
name_x = ['독립변수1', '독립변수2'],
name_w = 'Queen',
name_ds = '데이터셋명'
)
print(sem.summary)
# 핵심 확인: lambda(λ) 값·유의성, AIC가 OLS보다 낮은지
SLM이냐 SEM이냐 어떻게 고르냐? 가장 일반적인 방법은 OLS를 먼저 돌리고 나서 Lagrange Multiplier(LM) 검정을 이용하는 것이다. spreg의 OLS에서 spat_diag=True로 설정하면 자동으로 계산해준다. (LM은 2편에서 다룰 예정!)
의사결정 순서는 이렇다:
① LM-lag와 LM-error 중 하나만 유의하면 → 유의한 쪽 모형 선택 (LM-lag가 유의하면 공간시차모형(SLM)이 적합, LM-error가 유의하면 공간오차모형(SEM)이 적합)
② 둘 다 유의하면 → Robust LM-lag와 Robust LM-error를 비교해서 더 유의한 쪽 선택
③ 둘 다 유의하지 않으면 → 공간회귀 필요 없음, OLS 사용
④ 최종적으로 AIC/BIC로 OLS·SLM·SEM 세 모형을 비교하는 것도 좋다.
이번 1편에서는 공간통계의 출발점이 되는 개념들을 정리했다. OLS의 공간적 한계 → 공간자기상관의 개념 → Moran's I로 수치 측정 → 공간가중행렬로 이웃 정의 → SLM과 SEM으로 공간 구조를 모형에 반영하는 흐름이다. 2편에서는 Lagrange Multiplier(LM) 검정과 어디에 어떻게 군집이 있냐를 지역 단위로 파고드는 LISA와 Getis-Ord Gi*를 깊게 다룰 예정이다. 이상 끝! 📐