1편에서 OLS의 한계와 공간자기상관을 진단하는 Moran's I, 그리고 공간회귀 모형인 SLM과 SEM까지 다뤘다. 마지막에 SLM이냐 SEM이냐는 LM 검정으로 고른다고만 하고 넘어갔는데, 이번 편에서 그걸 제대로 짚고 가려고 한다.
2편에서는 LM 검정 완전 이해부터 시작해서 Moran's I의 한계를 넘어 지역별로 클러스터를 탐지하는 LISA와 Getis-Ord Gi*까지 정리해본다. 레츠꼬 📐
1. LM(Lagrange Multiplier) 검정 — SLM이냐.. SEM이냐..
1편에서 OLS를 돌리고 나서 잔차에 공간자기상관이 있다는 걸 확인했다면, 다음 질문은 당연히 이거다. "그래서 SLM을 써야 하나, SEM을 써야 하나?" 이론적으로만 생각하면 명확하지 않을 때가 많다. 데이터로 판단해야 한다. 이걸 도와주는 게 Lagrange Multiplier(LM) 검정이다.
LM 검정은 OLS 잔차를 기반으로 이 데이터에서 공간자기상관이 종속변수(SLM 방향)에서 오는지, 오차항(SEM 방향)에서 오는지를 통계적으로 진단해준다. 별도의 공간회귀 모형을 추정할 필요 없이 OLS 결과만 가지고 계산할 수 있어서 가볍고 빠르다.
LM 검정은 총 네 가지 통계량을 본다:
| 검정 통계량 | 설명 | 유의하면 (p < 0.05) | 유의하지 않으면 |
| LM-lag | 이웃의 y값이 내 y에 영향을 주고 있나? 를 본다 | → SLM | SLM X |
| LM-error | 오차끼리 공간적으로 연관되어 있나? 를 본다 | → SEM | SEM X |
| Robust LM-lag | SEM 효과를 걷어낸 뒤 순수하게 SLM이 필요한지 본다. 둘 다 유의할 때 사용. | → SEM보다 SLM이 더 적합 | SLM X |
| Robust LM-error | SLM 효과를 걷어낸 뒤 순수하게 SEM이 필요한지 본다. 둘 다 유의할 때 사용. | → SLM보다 SEM이 더 적합 | SEM X |
네 통계량 모두 카이제곱 분포를 따르고, 자유도 1 기준으로 유의수준 5%의 임계값은 3.84다. 통계량이 3.84보다 크면 귀무가설 기각이다.
2. LM(Lagrange Multiplier) 검정 이해하기
LM 검정을 좀 더 이해하고 싶다면 수식 구조만 살펴보면 된다.
LM-lag 수식:
$$LM_{lag} = \frac{\left( \frac{\mathbf{e}^{\top} W \mathbf{y}}{S^2} \right)^2}{(WX\hat{\beta})^{\top} M (WX\hat{\beta}) / S^2 + T}$$
복잡해 보이지만 분자를 보면 된다. e⊤Wy는 OLS 잔차(e)와 공간 래그된 종속변수(Wy)의 내적이다. 잔차가 이웃의 y값과 얼마나 연관되어 있냐를 측정하는 것이다. 이 값이 크면 클수록 SLM이 필요하다는 신호다.
LM-error 수식:
$$LM_{error} = \frac{\left( \frac{\mathbf{e}^{\top} W \mathbf{e}}{S^2} \right)^2}{T}$$
여기서 e⊤We는 OLS 잔차(e)와 공간 래그된 잔차(We)의 내적이다. 잔차들이 이웃 잔차와 얼마나 연관되어 있냐를 측정한다. 이 값이 크면 SEM이 필요하다. T는 W의 구조에서 오는 정규화 항이고, S²는 OLS 잔차 분산이다.
LM-lag와 LM-error가 둘 다 유의하게 나오는 경우가 많다. 이건 각 통계량이 서로의 영향을 통제하지 않기 때문이다. 이 문제를 해결하기 위해 Anselin et al. (1996)이 제안한 게 Robust LM이다.
Robust LM-lag:
$$RLM_{lag} = \frac{\left( \frac{\mathbf{e}^{\top} W \mathbf{y}}{S^2} - T \cdot \frac{\mathbf{e}^{\top} W \mathbf{e}}{S^2} \right)^2}{(WX\hat{\beta})^{\top} M (WX\hat{\beta}) / S^2}$$
Robust LM-lag의 분자에서 LM-error 쪽의 영향을 빼준다. 그래서 SEM의 영향이 통제된 상태에서 순수하게 SLM이 필요한지를 검정하는 것이다. Robust LM-error는 반대로 SLM 영향을 통제한 뒤 SEM 필요성을 본다. 둘 다 유의할 때는 Robust 통계량 중 더 유의한 쪽을 따르면 된다.
3. LM(Lagrange Multiplier) 검정 실전 — 어떻게 읽고 결정하나
의사결정 순서를 정리하면 이렇다:
① LM-lag만 유의 (LM-error는 유의하지 않음) → SLM 선택
② LM-error만 유의 (LM-lag는 유의하지 않음) → SEM 선택
③ 둘 다 유의 → Robust LM-lag vs Robust LM-error 비교 → 더 유의한(p-value 더 작은) 쪽의 모형 선택
④ 둘 다 유의하지 않음 → OLS 그대로 사용
⑤ 최종 확인 → OLS, SLM, SEM 세 모형의 AIC/BIC 비교해서 가장 낮은 쪽 선택
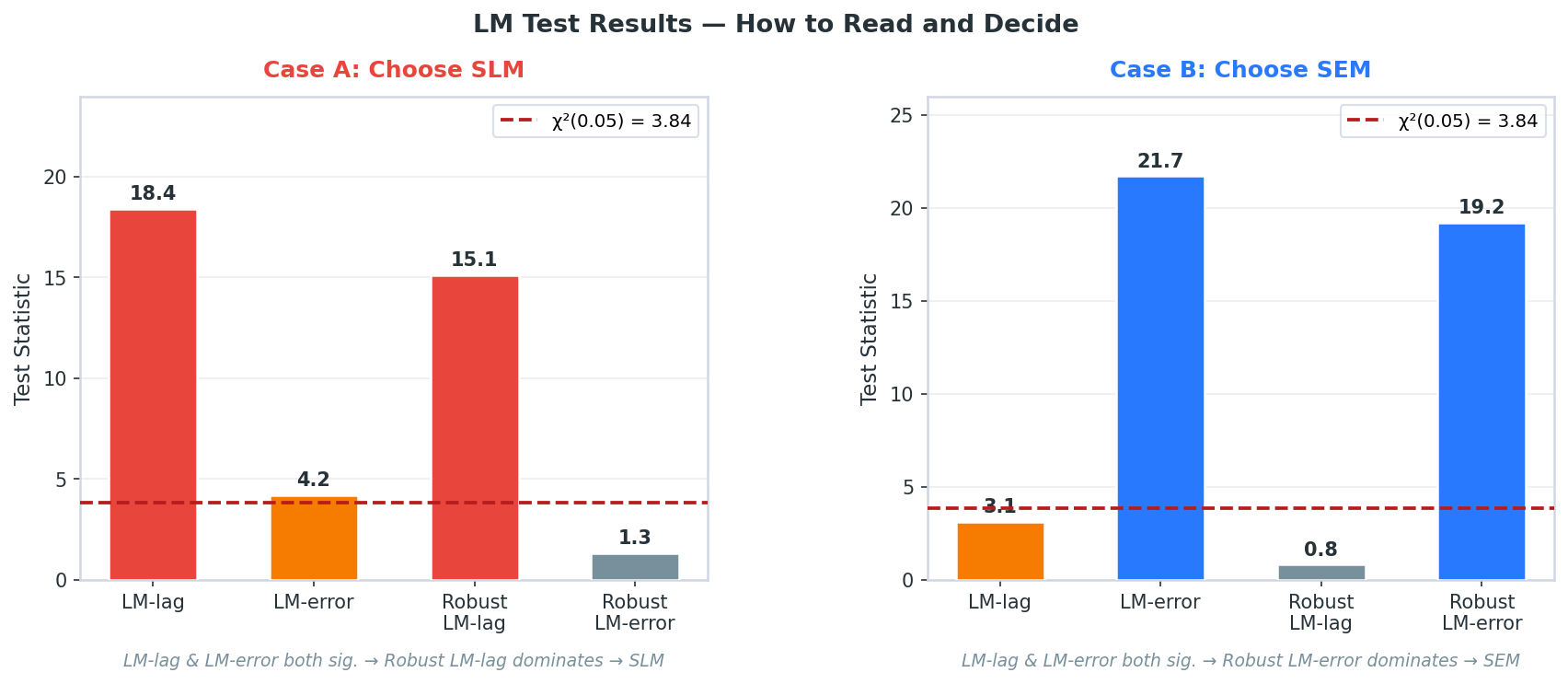
위 그림에서 Case A를 보면, LM-lag(18.4)와 LM-error(4.2)가 둘 다 임계값 3.84를 넘는다. 이 경우 Robust LM-lag(15.1)와 Robust LM-error(1.3)을 비교하는데, Robust LM-lag가 압도적으로 크니까 SLM을 선택한다. Case B는 반대로 Robust LM-error(19.2)가 dominant하므로 SEM 선택이다.
from spreg import OLS
# spat_diag=True 로 LM 검정 자동 계산
ols = OLS(
y = gdf[['종속변수']].values,
x = gdf[['독립변수1', '독립변수2']].values,
w = w_queen,
spat_diag = True,
name_y = '종속변수',
name_x = ['독립변수1', '독립변수2'],
)
print(ols.summary)
# 결과에서 확인할 항목 (DIAGNOSTICS FOR SPATIAL DEPENDENCE 섹션)
# -------------------------------------------
# TEST MI/DF VALUE PROB
# Moran's I (error) 1 X.XXX 0.XXX ← Moran's I on residuals
# Lagrange Multiplier (lag) 1 X.XXX 0.XXX ← LM-lag
# Robust LM (lag) 1 X.XXX 0.XXX ← Robust LM-lag
# Lagrange Multiplier (error)1 X.XXX 0.XXX ← LM-error
# Robust LM (error) 1 X.XXX 0.XXX ← Robust LM-error
# -------------------------------------------
# 판단 예시
lm_lag = ols.lm_lag[1] # p-value of LM-lag
lm_err = ols.lm_error[1] # p-value of LM-error
rlm_lag = ols.rlm_lag[1] # p-value of Robust LM-lag
rlm_err = ols.rlm_error[1] # p-value of Robust LM-error
if lm_lag < 0.05 and lm_err >= 0.05:
print("→ SLM 선택")
elif lm_err < 0.05 and lm_lag >= 0.05:
print("→ SEM 선택")
elif lm_lag < 0.05 and lm_err < 0.05:
if rlm_lag < rlm_err:
print("→ Robust LM-lag 우세: SLM 선택")
else:
print("→ Robust LM-error 우세: SEM 선택")
else:
print("→ 공간 의존성 없음: OLS 유지")
한 가지 주의사항: LM 검정은 OLS 잔차를 기반으로 하기 때문에 OLS 모형 자체가 잘 설정되어 있어야 신뢰할 수 있다. 변수 누락, 이분산(Heteroskedasticity), 비선형성이 있는 상태에서 나온 LM 검정 결과는 왜곡될 수 있다. LM 검정 전에 OLS 잔차 플롯과 기본 진단 검정을 먼저 확인하는 습관을 들이자.
4. 전역에서 국지로 — Moran's I의 한계
1편에서 Moran's I를 다뤘을 때 이런 말을 했다. "전역 통계이기 때문에 하나의 숫자로 뭉개진다." 이제 그 한계를 더 구체적으로 생각해보자.
예를 들어 서울시 자치구별 집값 데이터에서 Moran's I = 0.42, p < 0.001이 나왔다고 하자. 공간자기상관이 있다는 건 알겠는데, 이걸로는 다음 질문에 답할 수 없다:
· 어느 구가 핫스팟(비싼 지역끼리 뭉친 곳)인가?
· 어느 구가 콜드스팟(저렴한 지역끼리 뭉친 곳)인가?
· 주변과 유독 동떨어진 이상 지역은 어디인가?
· 클러스터가 통계적으로 유의한 지역은 정확히 어디인가?
이걸 알려면 전역(Global) 통계를 넘어 국지(Local) 통계가 필요하다. Moran's I를 각 지역 단위로 분해해서 계산하는 것이다. 이게 LISA다.
5. LISA — 지역별 공간 클러스터 탐지
LISA(Local Indicators of Spatial Association)는 1995년 Luc Anselin이 제안한 국지적 공간자기상관 지표다. Local Moran's I라고도 부른다. 핵심 아이디어는 전역 Moran's I 수식을 각 관측치 i에 대해 개별적으로 계산하는 것이다.
전역 Moran's I가 이렇게 생겼다면:
$$I = \frac{N}{S_0} \cdot \frac{\sum_i \sum_j w_{ij} z_i z_j}{\sum_i z_i^2}$$
Local Moran's I는 각 지역 i에 대해서만 계산한다:
$$I_i = \frac{z_i \sum_j w_{ij} z_j}{m_2}$$
여기서 zᵢ = (xᵢ - x̄) / s는 표준화된 값이고, m₂ = Σzᵢ²/N은 분산 정규화 항이다. Iᵢ가 양수이고 크면 → 지역 i와 이웃들이 비슷한 값 → 군집(HH 또는 LL). Iᵢ가 음수이면 → 지역 i와 이웃들이 반대 방향 → 이상값(HL 또는 LH).
LISA는 각 지역을 아래 4가지 유형으로 분류한다. Moran Scatter Plot의 4분면과 정확히 일치한다:
| 유형 | Iᵢ 부호 | 조건 | 해석 |
| HH | 양수 (+) | zᵢ > 0 이고 Wzᵢ > 0 — 나도 높고 이웃도 높음 | 핫스팟 — 고밀도 군집 중심 |
| LL | 양수 (+) | zᵢ < 0 이고 Wzᵢ < 0 — 나도 낮고 이웃도 낮음 | 콜드스팟 — 저밀도 군집 중심 |
| HL | 음수 (-) | zᵢ > 0 이고 Wzᵢ < 0 — 나는 높은데 이웃은 낮음 | 공간 이상값 — 돌출된 고값 지역 |
| LH | 음수 (-) | zᵢ < 0 이고 Wzᵢ > 0 — 나는 낮은데 이웃은 높음 | 공간 이상값 — 함몰된 저값 지역 |
중요: LISA 결과는 반드시 통계적 유의성 검정을 통과한 지역만 색칠해야 한다. p-value 없이 단순히 사분면 위치만으로 색칠하면 그건 LISA 클러스터 맵이 아니라 그냥 Moran Scatter Plot을 지도에 투영한 것이다. 유의성 검정은 Monte Carlo permutation을 사용한다. W행렬 구조를 유지한 채로 값을 무작위로 섞어서 귀무분포를 만들고, 실제 Iᵢ가 그 분포에서 얼마나 극단적인지를 본다. 보통 999번 permutation을 사용한다.

from esda.moran import Moran_Local
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
# Local Moran's I 계산 (999 permutations)
lisa = Moran_Local(gdf['변수명'], w, permutations=999)
# 사분면 코드: 1=HH, 2=LH, 3=LL, 4=HL (esda 기준)
gdf['lisa_q'] = lisa.q
gdf['lisa_sig'] = lisa.p_sim < 0.05 # 유의한 지역만
# 색상 매핑 — 유의하지 않으면 회색
color_map = {1:'#ffcdd2', 2:'#e1bee7', 3:'#bbdefb', 4:'#ffe0b2'}
gdf['color'] = gdf.apply(
lambda r: color_map.get(r['lisa_q'], '#f5f5f5')
if r['lisa_sig'] else '#f5f5f5', axis=1)
# 시각화
fig, ax = plt.subplots(figsize=(10, 8))
gdf.plot(color=gdf['color'], edgecolor='white', linewidth=0.5, ax=ax)
legend_items = [
mpatches.Patch(facecolor='#ffcdd2', label='HH — Hot Spot'),
mpatches.Patch(facecolor='#bbdefb', label='LL — Cold Spot'),
mpatches.Patch(facecolor='#ffe0b2', label='HL — Outlier'),
mpatches.Patch(facecolor='#e1bee7', label='LH — Outlier'),
mpatches.Patch(facecolor='#f5f5f5', label='Not Significant'),
]
ax.legend(handles=legend_items, loc='lower right', fontsize=10)
ax.set_title("LISA Cluster Map (p < 0.05)", fontsize=14, fontweight='bold')
plt.tight_layout()
plt.show()
# 결과 요약
print(gdf[gdf['lisa_sig']]['lisa_q'].value_counts())
# 1: HH 2: LH 3: LL 4: HL
LISA 결과를 볼 때 한 가지 더 체크해야 할 게 있다. 다중 검정 문제(Multiple Testing Problem)다. N개 지역에 대해 각각 유의성 검정을 하면, 우연히 유의하게 나오는 지역이 생길 수 있다. 엄격하게 하려면 Bonferroni 보정이나 FDR(False Discovery Rate) 보정을 적용하기도 한다. 실무에서는 p < 0.05 기준을 많이 쓰지만, 탐색적 분석임을 염두에 두고 해석해야 한다.
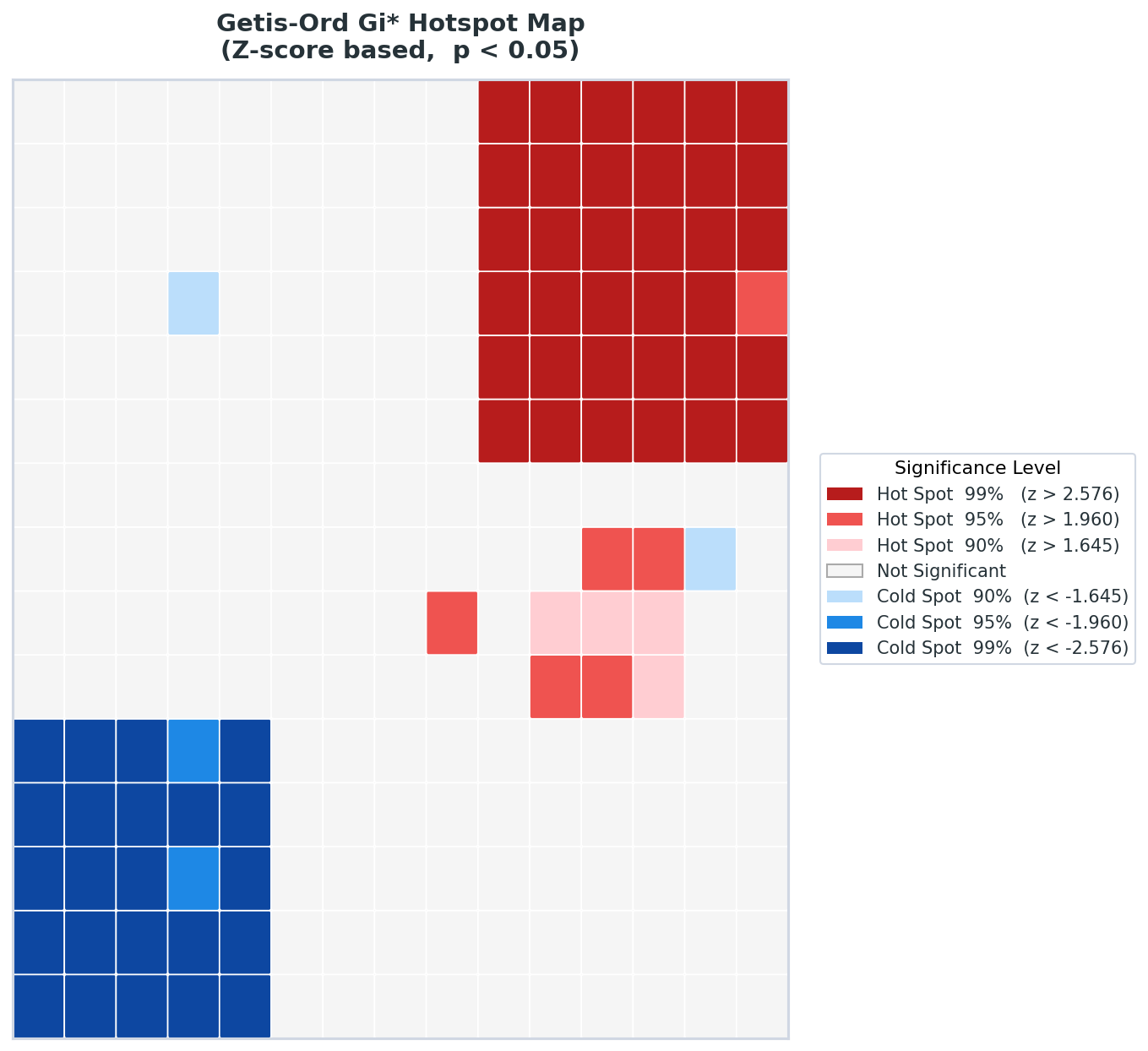
6. Getis-Ord Gi* — 핫스팟의 강도를 Z-score로
LISA와 함께 핫스팟 분석의 양대 산맥인 Getis-Ord Gi*(지-스타)다. 1992년 Getis와 Ord가 제안했고, 1995년 Ord와 Getis가 자기 자신을 포함하는 Gi* 버전으로 개선했다.
Gi* 수식은 이렇다:
$$G_i^* = \frac{\sum_j w_{ij} x_j - \bar{X} \sum_j w_{ij}}{S \sqrt{\frac{n \sum_j w_{ij}^2 - \left(\sum_j w_{ij}\right)^2}{n-1}}}$$
분자를 보면 이웃들의 가중 합(Σwᵢⱼxⱼ)에서 전체 평균 × 이웃 가중치 합(X̄ · Σwᵢⱼ)을 뺀다. 즉, 이 지역과 그 이웃들의 값 합이 전체 평균에서 얼마나 벗어나 있냐를 본다. 분모는 정규화 항이다. 결과는 Z-score로 나온다.
LISA와 비교했을 때 핵심 차이가 하나 있다. Gi*는 자기 자신(i)을 이웃에 포함해서 계산한다. 그래서 내가 속한 지역 전체가 평균보다 높냐 낮냐를 본다. 반면 Local Moran's I는 자신을 제외한 이웃과의 관계를 본다.
| 구분 | LISA (Local Moran's I) | Getis-Ord Gi* |
| 수식의 기준값 | 이웃들의 가중 평균 vs 자신 | 자신 + 이웃들의 총합 vs 전체 평균 |
| 자기 포함 여부 | 자신 제외 | 자신 포함 (Gi*) |
| 출력 결과 | 군집 유형 코드 (HH/LL/HL/LH) | Z-score (연속값) |
| 이상값 탐지 | 가능 (HL, LH 식별) | 불가 (군집만 탐지) |
| 강도 표현 | 유의/비유의 이진 분류 | 신뢰수준 99/95/90%로 세분화 |
| 활용 | 군집 구조 + 이상값 동시 파악 | 핫스팟/콜드스팟 강도 매핑 |
from esda.getisord import G_Local
# Gi* 계산 (star=True: 자기 포함)
gi_star = G_Local(gdf['변수명'], w, star=True, permutations=999)
gdf['gi_z'] = gi_star.Zs # Z-score
gdf['gi_p'] = gi_star.p_sim # Monte Carlo p-value
# 신뢰수준별 분류
def classify_hs(z, p):
if p >= 0.1: return 'Not Significant'
if z > 0:
if p < 0.01: return 'Hot Spot 99%'
elif p < 0.05: return 'Hot Spot 95%'
else: return 'Hot Spot 90%'
else:
if p < 0.01: return 'Cold Spot 99%'
elif p < 0.05: return 'Cold Spot 95%'
else: return 'Cold Spot 90%'
gdf['gi_class'] = gdf.apply(
lambda r: classify_hs(r['gi_z'], r['gi_p']), axis=1)
print(gdf['gi_class'].value_counts())
# Z-score 기준으로 직접 판단할 경우 (p_sim 없을 때)
# |Z| > 2.576 → 99%, |Z| > 1.960 → 95%, |Z| > 1.645 → 90%
Gi*의 Z-score가 높다는 건 그 지역과 주변 지역 전체가 평균보다 유의하게 높다는 것이다. 단순히 "옆이 높다"가 아니라 "내가 속한 덩어리 전체가 높은 값으로 뭉쳐있다"는 더 강한 진술이다. 그래서 Gi*는 범죄 집중 지역, 전염병 확산 중심, 부동산 과열 지역처럼 공간적 집중 현상의 강도를 지도로 표현할 때 특히 유용하다.
7. LISA vs Gi* — 같은 데이터, 다른 시각
두 방법을 같은 데이터에 적용하면 어떻게 다른 결과가 나오는지 보자.
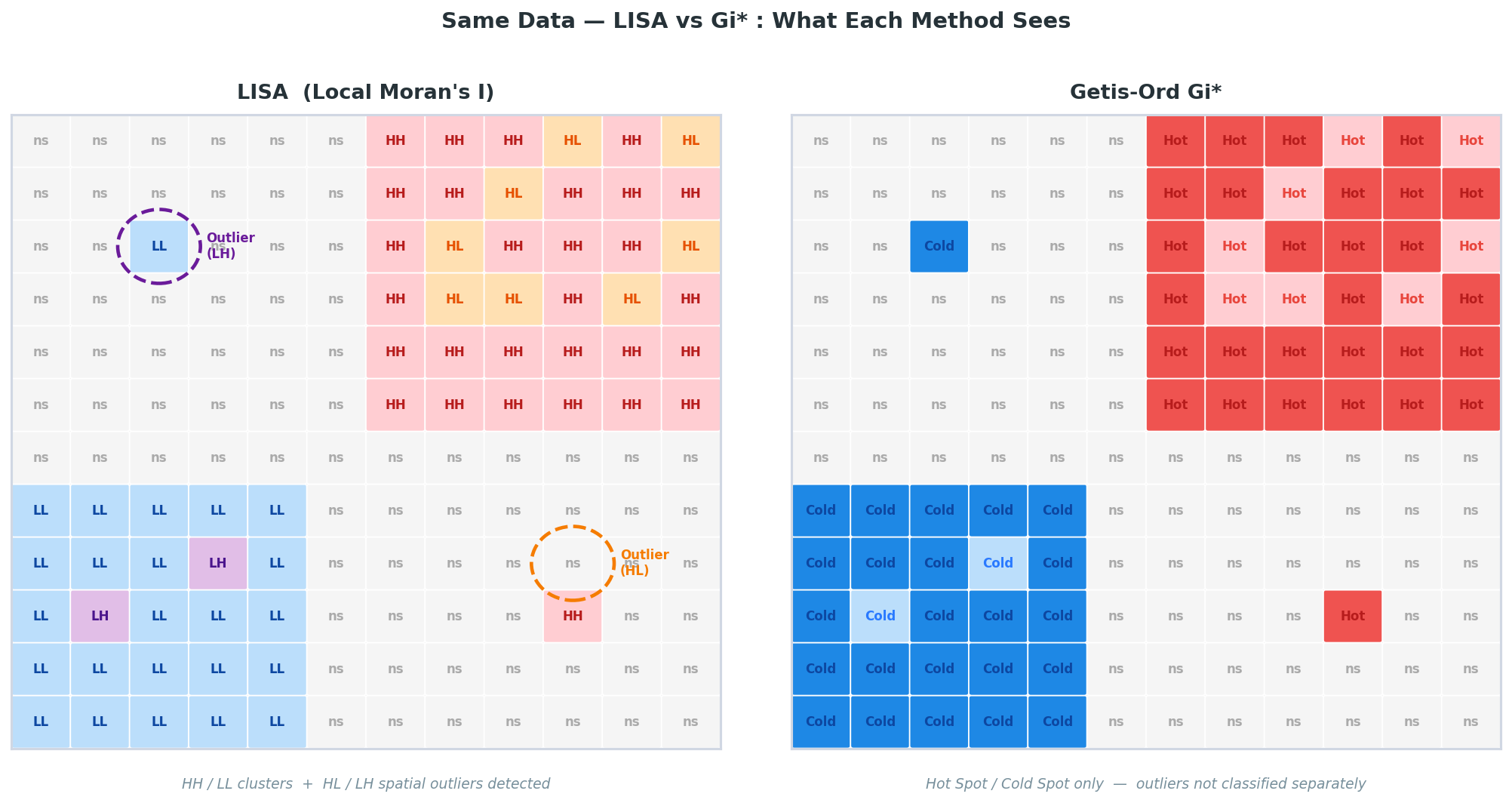
위 그림에서 가장 눈에 띄는 차이가 오른쪽 아래 구석의 HL 이상값과 왼쪽 위 구석의 LH 이상값이다. LISA에서는 이 지역들이 명확히 HL/LH 이상값으로 분류되는데, Gi*에서는 그냥 Hot/Cold Spot 군집의 일부로 흡수된다. Gi*는 "이 지역이 주변보다 높은가"만 볼 뿐, "이 지역이 주변과 반대 방향인가"는 보지 않기 때문이다.
실무에서 어떤 걸 쓸지는 연구 목적에 따라 달라진다. 공간 이상값(spatial outlier)도 중요한 분석 대상이라면 LISA, 핫스팟/콜드스팟의 강도와 신뢰수준을 세밀하게 보고 싶다면 Gi*를 쓰면 된다. 사실 둘 다 돌려보고 결과를 비교하는 게 가장 좋다. 서로 보완적인 정보를 주기 때문이다.
2편에서는 LM 검정으로 SLM/SEM 선택 기준을 잡고, Moran's I의 한계를 넘어 지역 단위로 파고드는 LISA와 Gi*까지 정리했다. 3편에서는 회귀계수 자체가 공간에 따라 달라지는 공간적 비정상성(Spatial Non-stationarity)을 다루는 GWR과 MGWR을 깊게 파볼 예정이다. 이상 끝! 🗺️